Project Release-Notes Supplemental-Manual_PeerReview-S1 
![]()
![]()
![]()
press '[' to toggle the sidebar

Scalable Framework for Importance Sampling (Infinite-Sites) in Population Genetics May 18, 2014
a Reproducible Research as Championed by Victoria Stodden
| Background Color | ||
|---|---|---|
| ||
Importance Sampling (IS): A Scalable Framework |
| Section | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|


| Background Color | ||
|---|---|---|
| ||
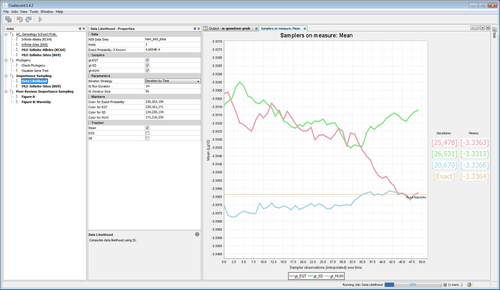
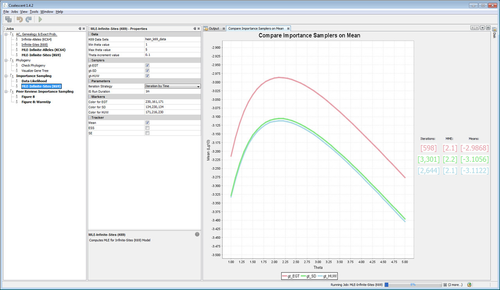
Importance Sampling (IS): Computing Likelihood |
| Section | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Background Color | ||
|---|---|---|
| ||
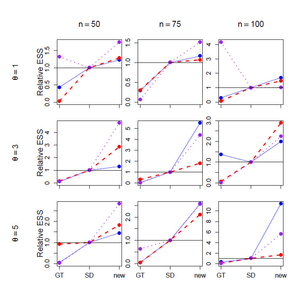
Importance Sampling (IS): Innovation - Significance of running Time |
| Section | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|

| Background Color | ||
|---|---|---|
| ||
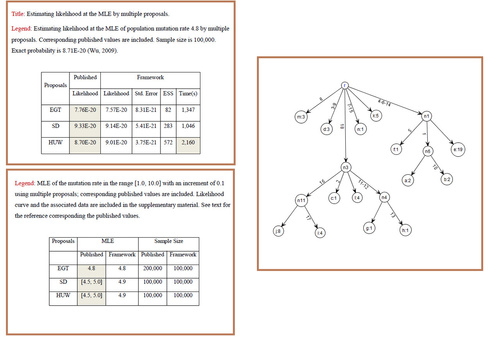
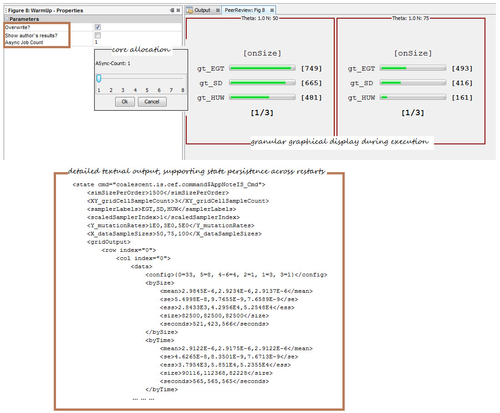
Updates: Exact Probability & Phylogeny |
| Section | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Info | ||
|---|---|---|
| ||
© 2009-2014 Susanta Tewari. All rights reserved | Have you encountered a bug in Coalescent? Want to suggest a new feature? Use Contact Support |



