Coalescent-1.4.2
Release Notes Supplemental-Manual_PeerReview-S1 
![]()
![]()
![]()
press '[' to toggle the sidebar

Scalable Framework for Importance Sampling (Infinite-Sites) in Population Genetics May 13, 2014
a Reproducible Research as Championed by Victoria Stodden
Importance Sampling (IS): A Scalable Framework
General framework for importance sampling, to compute data likelihood under the infinite sites model of mutation. Key concepts: Sampler, Proposal and Factor.
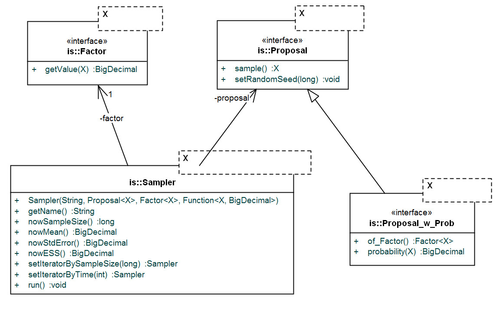
Extension of the general framework for the domain of genealogies in Coalescent theory.
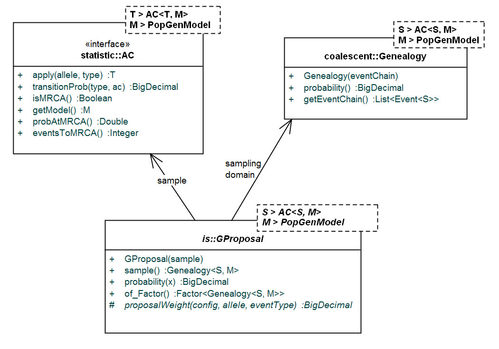
Implementations of the standard proposals for infinite-sites model of mutation: EGT, SD and HUW.

Importance Sampling (IS): Computing Likelihood
A user-friendly job for computing likelihood under infinite-sites model of mutation using multiple proposals together. Both textual and graphical output are provided. Output clearly shows relative efficiency of the proposals in terms of error and running time. Effective sample size is also computed.The job automatically uses multi-core hardware, if available. Sampling can be run using various iteration strategies: number of realizations, time or data-OrderUnit (data order is defined by the sum of total alleles and the number of mutations less one). Progress indicator clearly shows the amount of work done. Exact probability can also be plotted, if known. If the application has computed exact probability for a data set, then that value is plotted when the importance sampling is done for the same data set.
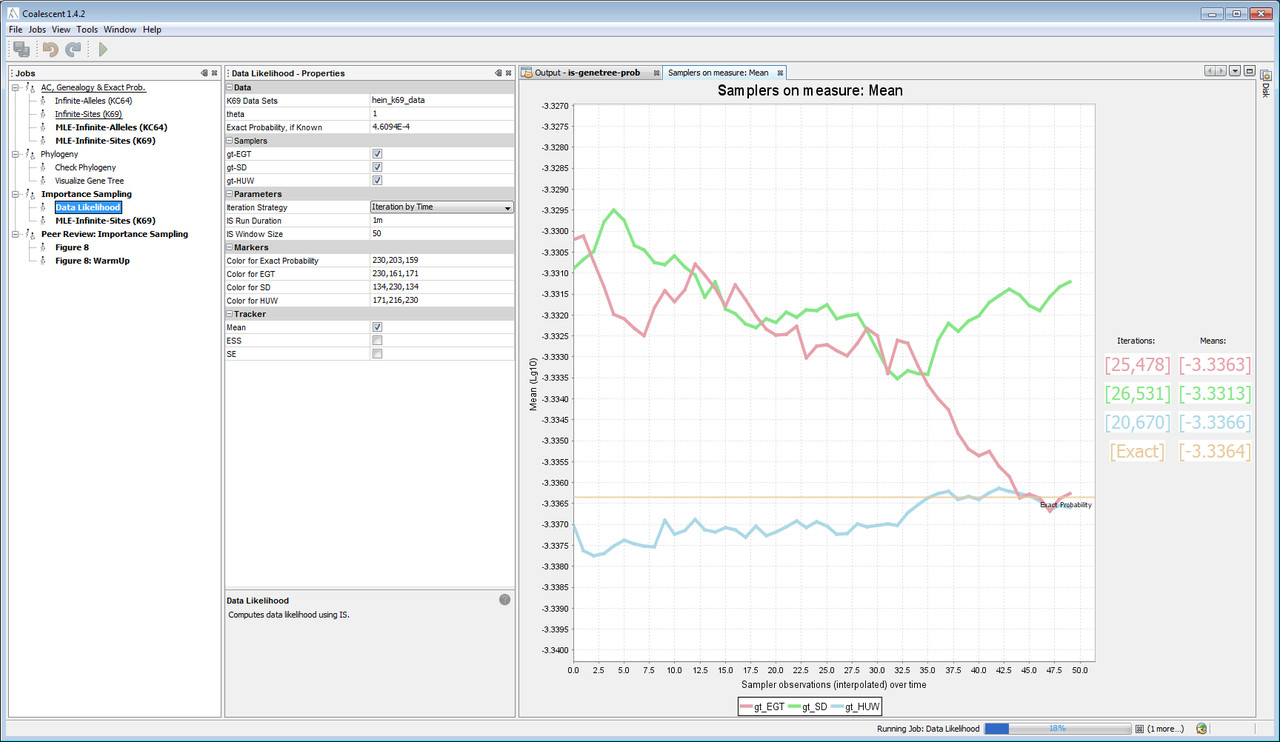
The maximum likelihhod estimator for the mutation parameter can be found over a range of parameter values, using mutiple proposals. most of the features similar to computing likelihood are also available here.
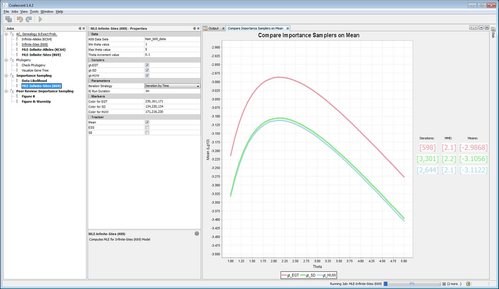
Framework validates the published values in the literature for the benchmark data set (drawn below using this framework) in Griffiths & Tavaré, 1994.
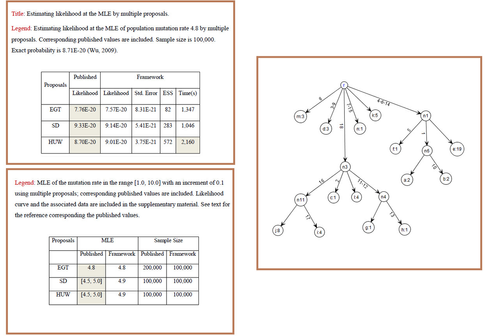
Importance Sampling (IS): Innovation - Significance of running Time
The following are the currently known proposals for computing likelihod under infinite sites mode of mutation. They all share the same framework code and as such running time reflects the inherent computing time. The known order of efficiency among these proposals is: EGT < SD <HUW

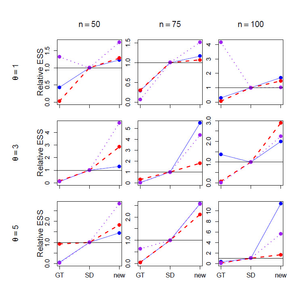
The following figure verifies the results in (Hobolth, Uyenoyamay & Wiuf, 2008), but shows that when the figure of merit is ESS per running time, EGT < HUW < SD, where SD is only slightly better than HUW.
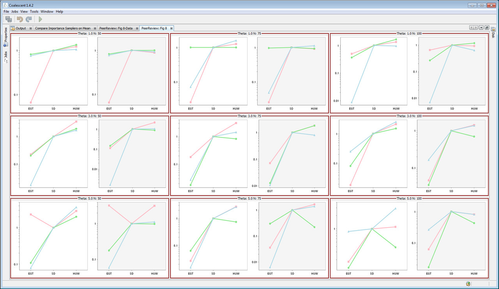
Reviewer Friendly: Facilities added to help reproduce Figure 8 on the user machine. This is a long running job which computes likelihood for a reasonably large data 54 times (9 cells × 3 replicates × 2 by-size-and-time). Facilities include allocating more cores, persisting computation state across restarts, detailed textual output, granular graphical display during execution, displaying packaged author`s results and a warmup job that is similar but takes 1% time of the original job to give a quick overview.
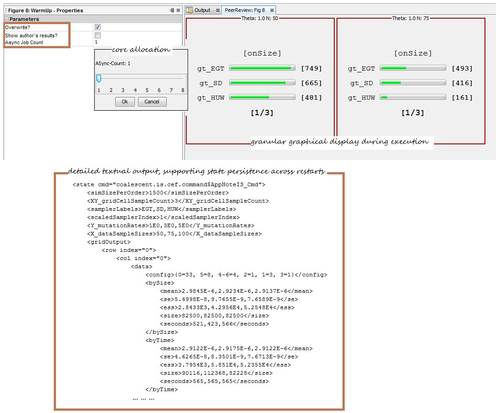
Updates: Exact Probability & Phylogeny
Maximum Likelihood Estimation using exact probability for both infinite-alleles and infinite-sites models of mutation. Control for inifnite-alleles data accepts infinites-sites data as well. Ewens Sampling Formula added as a choice of algorithm (besides recursion) for computing the exact probability.
Exact probability computed using the application is stored as meta information for the corresponding data set and the mutation parameter. When such data set is used with Importance Sampling (IS) based methods (benchmarking, for example), the exact probability is pulled automatically and plotted in the graph. This helps compare the accuracy of various samplers as this measure is free of monte-carlo approximations.
Supported by: ![]()

![]() Powered by:
Powered by:![]()

